Contents
Kinship&Genealogy
Kinship Introduction
Learning Kinship with
Use the Kinship Editor
Kinship Editor Results
At the end of the prolog program that represents the Kinship Editor data, we added some additional prolog rules:
child(Child,Ego) :- sibset(Child,ID), spouseset(Ego,ID).
which is read, Child is a child of Ego if the sibset id of Child is the id of Ego's spouseset.
spouse(Spouse,Ego) :- spouseset(Spouse,ID), spouseset(Ego,ID), neq(Spouse,Ego).
which is read, Spouse is spouse of Ego if Spouse and Ego share a spouseset id
sibling(Sibling,Ego) :- sibset(Sibling,ID), sibset(Ego,ID), neq(Sibling,Ego).
which is read, Sibling is sibling of Ego if Sibling and Ego share a sibset id
These statements do not contain new information. Instead, they describe structural relationships between different categories. In this case they permit us to translate information from a form that is abstractly useful (for reasons discussed at considerable length in the Specification section) to categories that people are more accustomed to use when thinking about genealogical relationships. In Prolog these kinds of statements which transform and classify are usually called rules, opposed to data, or these are usually called in Prolog facts. The ':-' indicates that a new rule is being defined. The left-hand side of the rule is the result of the rule (called the head), the right-hand side is the definition of the rule (or body).
You should note the use of 'spouse' and 'Spouse' above. In prolog, names always begin with lowercase letters (a-z). If a term begins with an uppercase letter (A-Z), it is regarded as a variable, a reference to a value that is not set at the time of writing the rule, but will be filled in when the rule is used in context with actual data. This child rule could have been written
child(X,Y) :- sibset(X,Z), spouseset(Y,Z).
and it would work exactly the same way. All that is important is that the variable for each position be different. Variables that are spelt the same, such as Z above are assumed to have a common value wherever they appear in the rule. X and Y can have the same value, but can refer to different values. Since we want to relate two people, we need two different variables to reference them. Since we want to match on a single ID, we use the same name (Z) for the id. The rule will only be 'true' if there are two individuals where one has a sibset id that is identical to the others spouseset id. To solve this rule prolog has to evaluate the body of the rule, the statements to the right of the ' :-' (which I read as when). In the child rule this involves seeing if there are facts that support the two conditions for truth. If both conditions are true, then the variables in the goal (the bit to the left of the ' :-' are set to the corresponding variables in the body of the rule.
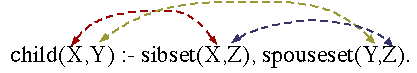
The child rule works by looking at prolog facts, the direct representation of the information collected by the Kinship Editor. This is useful, because although no new primary data for individuals is being added by a rule, structural information is being added. Prolog facts tend to introduce individualised information, Prolog rules tend to add general paradigmatic information; information that is true for more than a single individual. So while each person potentially has a specific sibset, parental spouseset and one or more spousesets, the child rule holds for everyone, the generally recognised relationship child is derived for each person from their specific details.
Rules can be based on rules as well. We derive the parent rule from the child rule. This rule exploits the polarity of the child/parent relationship: If X is child to Y, then Y is parent to X. This is a general structural relationship that holds for all Xs and Ys. If we have a specific group of people, then we can apply this rule, and identify all the parent relationships in that group.
Next section: Trying things out